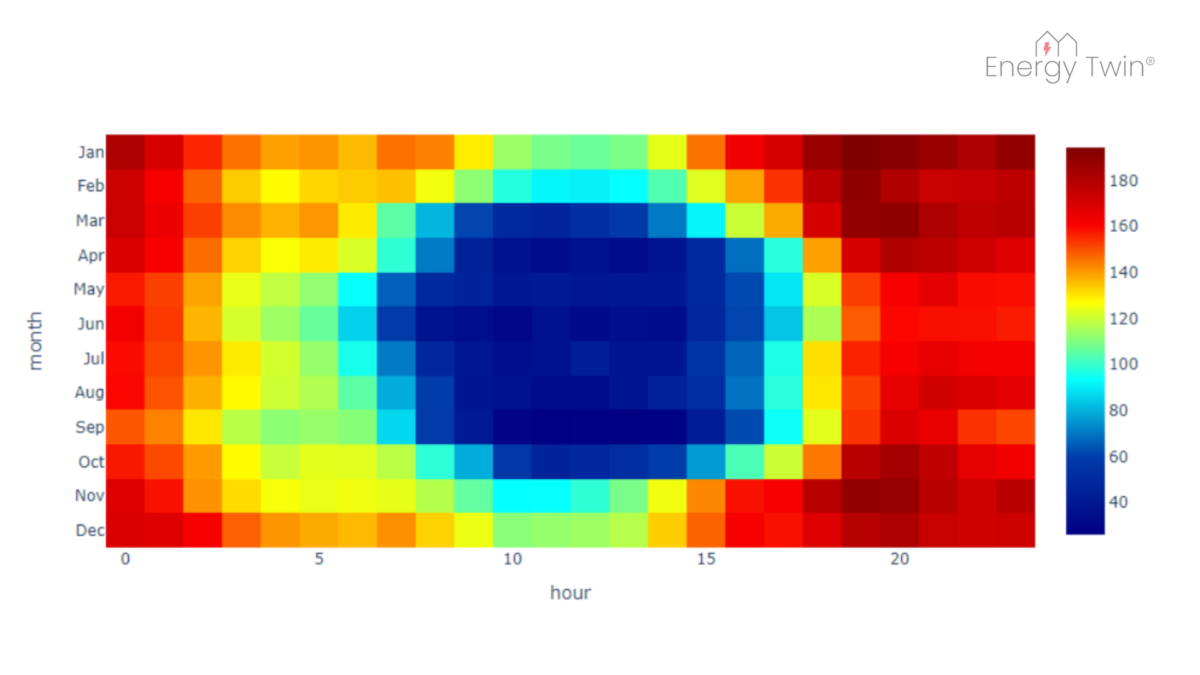
In the realm of energy data evaluation, machine learning models have unlocked significant potential. These tools support everything from energy conservation analysis to anomaly detection and optimization. But at the heart of any successful application lies one essential ingredient: a model that accurately reflects how buildings operate in the real world.
One often-overlooked challenge in achieving this reliability lies in managing the different operating regimes of a building. While weekly or monthly data evaluations may overlook these nuances, interval data analysis (e.g., hourly or 15-minute intervals) demands a deeper understanding of how building operation changes over time. In this newsletter, we explore how to address this challenge by distinguishing between occupied and unoccupied days and properly accounting for holidays.
Start with the Basics: Occupied vs. Unoccupied Days
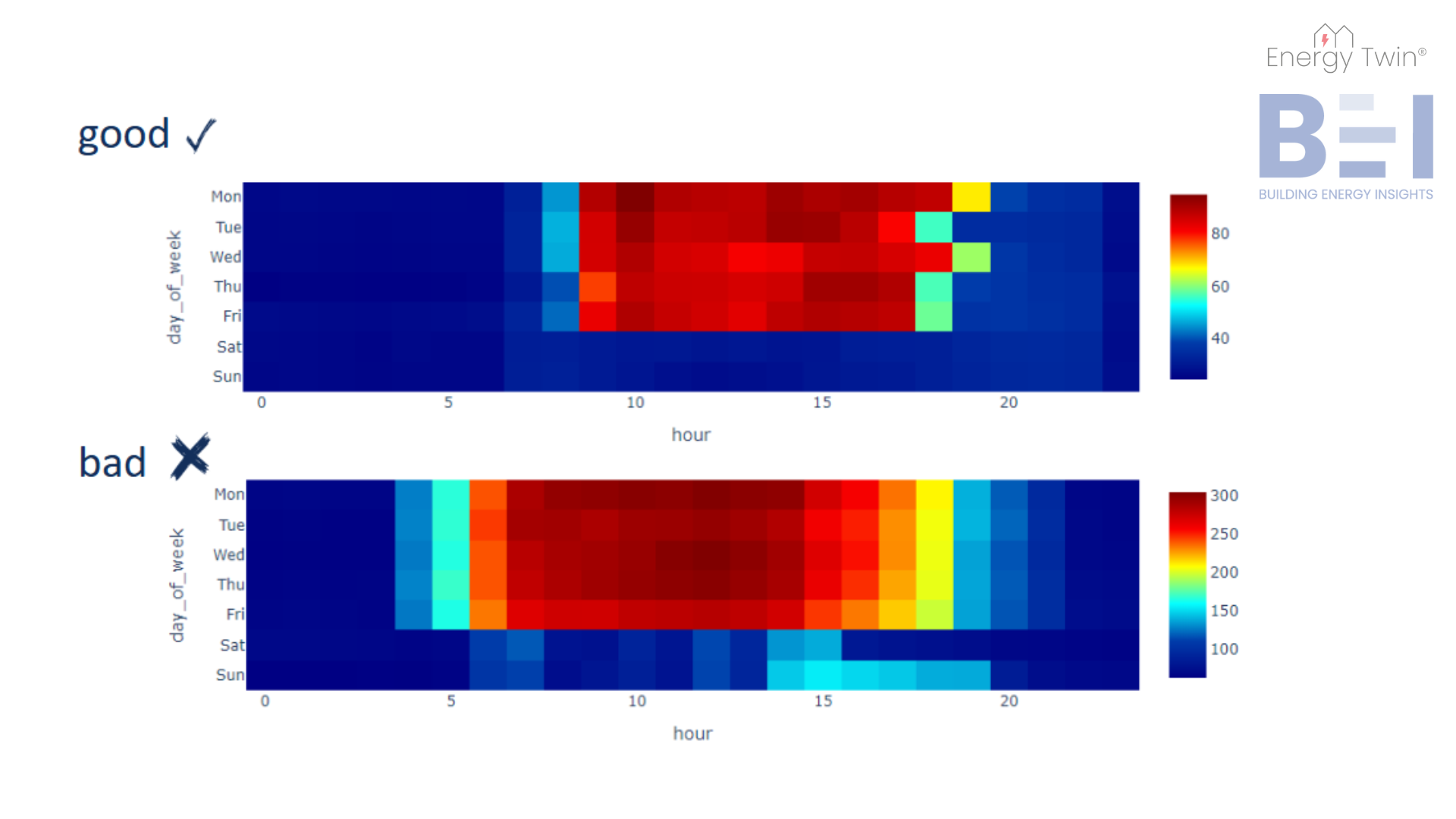
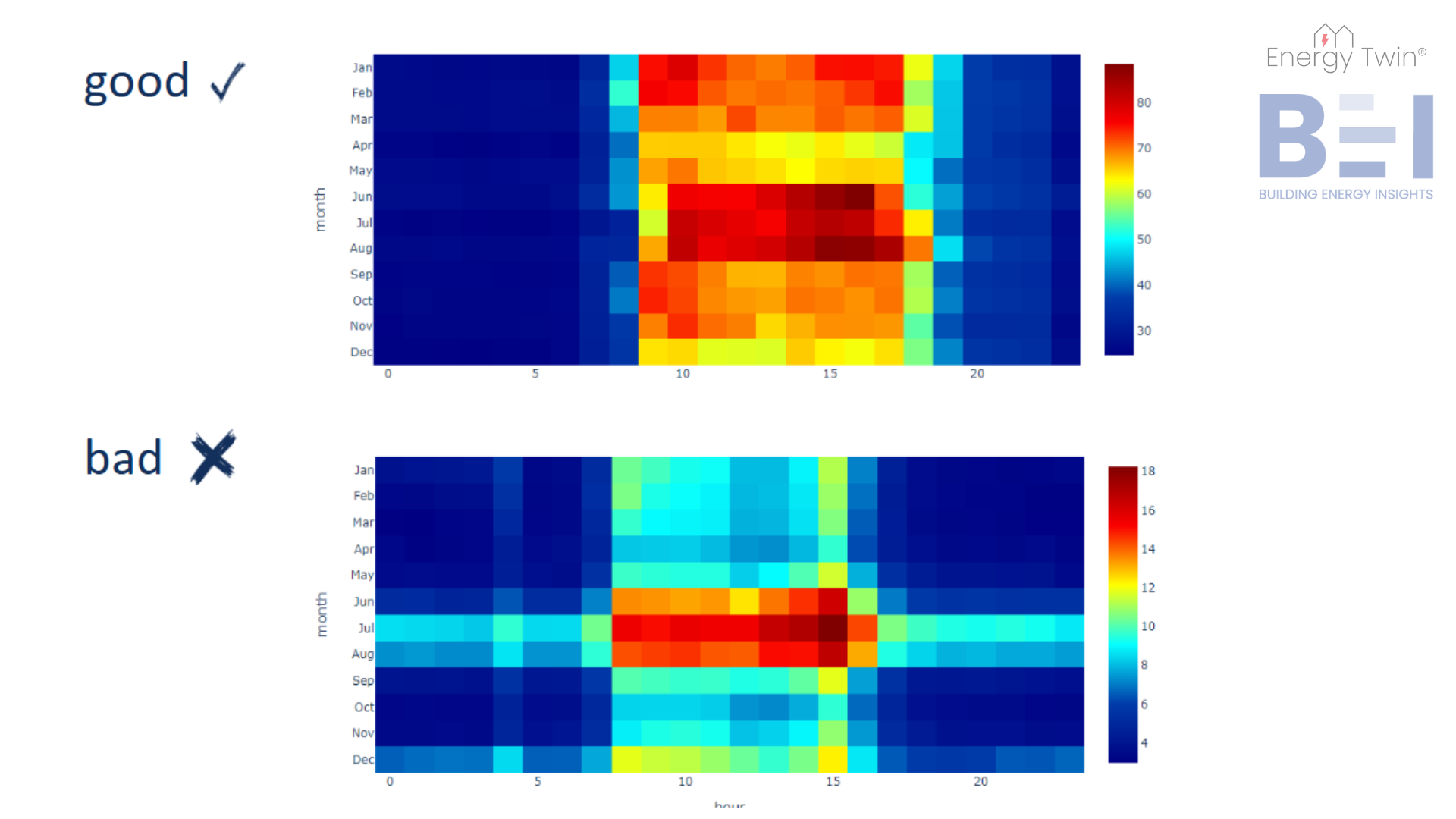
Commercial buildings frequently exhibit markedly different energy consumption patterns during workdays versus weekends. For simplicity, let’s assume the building is unoccupied during weekends, with a typical energy setback in place. This means reduced base consumption and adjusted weather-related loads reflecting heating or cooling setbacks.
Level Up Your Model: Don’t Ignore Holidays
Holidays pose unique challenges. They may seem insignificant due to their low frequency, but failing to address them can undermine model accuracy. For instance, if a model assumes a holiday is a regular weekday, the unusually low consumption may be misclassified—skewing predictions or masking anomalies.
That’s why we treat holidays as their own category, distinct from both weekdays and weekends. By recognizing their unique behavior, we turn potential outliers into expected patterns – improving model stability and predictive power.
A Real-World Example
Imagine we’re identifying a model using only three months of data – specifically Q2 2023. In the Czech Republic, this period includes four public holidays, three of which fall on a Monday. How does that influence the outcome?
In the chart below, you can see a comparison of two models on a regular week in February, when no public holidays occurred:
- The blue line represents a model identified on Q2 2023 data with public holidays correctly taken into account.
- The green line shows a model identified on the same data without accounting for holidays.
- The red line shows actual measured consumption.
A Real-World Example
Imagine we’re identifying a model using only three months of data – specifically Q2 2023. In the Czech Republic, this period includes four public holidays, three of which fall on a Monday. How does that influence the outcome?
In the chart below, you can see a comparison of two models on a regular week in February, when no public holidays occurred:
- The blue line represents a model identified on Q2 2023 data with public holidays correctly taken into account.
- The green line shows a model identified on the same data without accounting for holidays.
- The red line shows actual measured consumption.

Notice how the green line significantly underestimates Monday consumption. By treating holidays as regular weekdays, the model learned an unrealistically low baseline – introducing a bias of more than 25 kW from just a few misclassified days. Why does this happen? In this case, 3 out of the 13 Mondays in the training data were public holidays. Without that context, the model tried to minimize error across all Mondays, combining regular and atypical days into a single profile. This pulled the expected load for Mondays lower, resulting in a distorted time-dependent pattern that doesn’t reflect actual operations.
How do we handle holidays correctly to avoid this kind of mistake? It comes down to two things: identifying them accurately and modeling them appropriately.
Step One: Defining Holidays Automatically
Manually managing holiday calendars can be tedious and error-prone; especially when working with buildings across multiple countries or regions. At Energy Twin, we avoid this complexity by using a location-aware API (namely this great service https://date.nager.at/ ) that automatically downloads public holidays based on each building’s location.
Step Two: Modeling Holidays Properly
Once holidays are identified, how should they be treated in the model? Should they behave like Sundays? Or should each holiday have its own profile? Modeling every holiday separately and ensuring that statistical properties of training data are met is not realistic (you do not have enough data to model each holiday separately). At the same time, lumping them in with weekends oversimplifies their unique patterns.
One method to find the right balance, used in our approach as well, is to define an “eighth weekday” for TOWT modeling. This captures the distinct behavior of holidays without overfitting, helping your model remain both generalizable and precise.
Conclusion
When weekend or holiday behavior is oversimplified, it can distort the entire model, leading to misleading savings estimates or missed anomalies. By clearly separating weekdays, weekends, and holidays, and capturing their temperature-driven dynamics, models better reflect real-world building operations.
This is especially important when following M&V (Measurement & Verification) guidelines, which typically require an R² above 0.75 and a CV(RMSE) below 25%. A model that previously failed to meet these criteria can suddenly fall into compliance by explicitly handling these exceptions. This reduces error, improves accuracy, and builds trust in your analytics.
When every day matters, holidays included, it’s worth taking the extra step to model building behavior as it truly occurs. That’s the kind of detail that helps turn data into decisions – and it’s a key part of the approach we take at Energy Twin.