Companies often understand the importance of deploying smart meters and getting data online. They see it as a key milestone—and while it is, it’s only the beginning of the journey. As mathematicians say, this is a “necessary condition” but not a “sufficient condition.” Without proper utilization, the full potential of your smart metering investment remains untapped. Let’s explore some common misconceptions and mistakes made in this space.
Mistake #1: Focusing on Visual Style and “Gadgets”
Making energy data accessible on a tablet, phone, or PC is useful—but that alone doesn’t mean you’re leveraging it effectively. Too often, decision-makers focus on the appearance of dashboards and the appeal of new gadgets, prioritizing style over substance. While good design can enhance usability, it’s one of the least important factors in an effective energy management system. The real value isn’t in how the data looks, but in how it’s processed and analyzed to extract actionable insights that drive real impact.
Mistake #2: Lack of Computational Capabilities
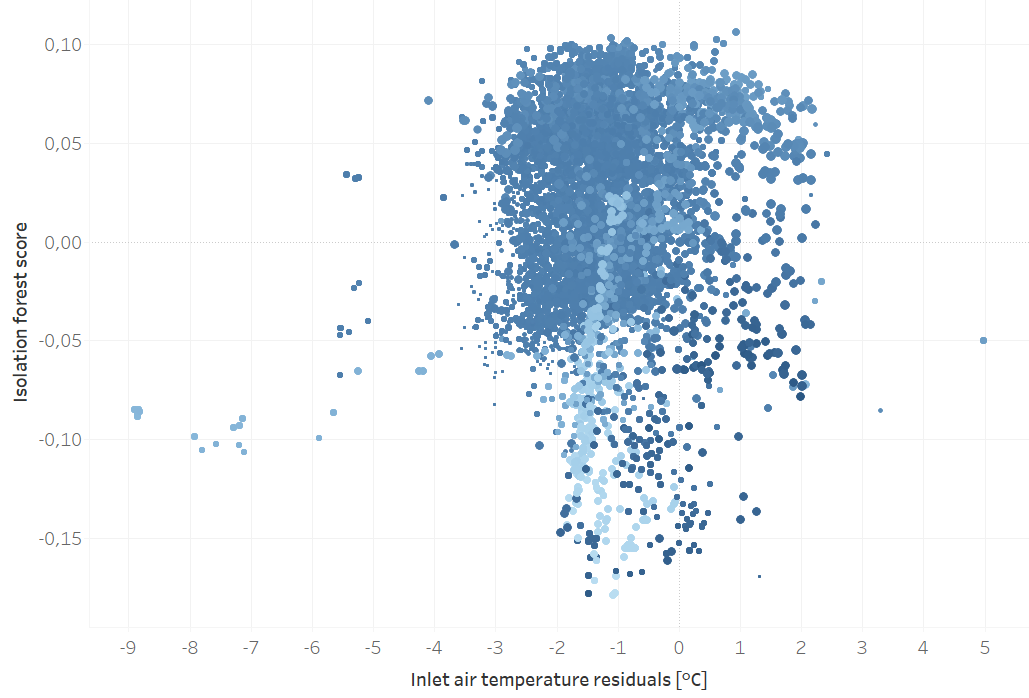
Many energy software tools offer basic charting features, allowing users to compare energy consumption across time periods, like months or years. Some even incorporate weather normalization through degree days. While these functions are useful, they fall short when dealing with smart meter data, which often comes in 15-minute intervals. This level of granularity introduces a new challenge—one that requires more advanced computational methods than simple charts or weather adjustments can offer.
Most software platforms aren’t built to harness the full power of these high-frequency data streams. Advanced machine learning (ML) algorithms can uncover hidden patterns, enabling businesses to improve efficiency and optimize performance. Without these computational tools, companies miss out on valuable insights, ultimately leaving much of their smart metering investment underutilized.
Mistake #3: Expecting One Tool to Solve Everything
In many Requests for Proposals (RFPs), companies look for an all-in-one solution—software that can handle everything from data collection and compliance reporting to invoicing, tariff calculations, forecasting, and AI-driven analytics. Ideally, they want a system that does it all with a single click while adhering to local regulations.
However, expecting one tool to excel in all these areas is unrealistic, especially given the diverse and region-specific requirements in the energy sector. Instead, companies should prioritize creating an independent data layer—a centralized repository where energy data is accessible via APIs. This approach allows for modularity, enabling you to integrate and replace specialized tools as needed without vendor lock-in. With this setup, each component of the ecosystem performs at its best while remaining seamlessly connected to the larger system.
Conclusion
Building an effective energy management system isn’t just about installing smart meters or selecting a single software solution—it’s about creating a foundation that is both flexible and future-proof. The key lies in establishing an independent data layer, a centralized hub where energy data remains accessible via APIs. This ensures seamless integration across different tools and systems, giving businesses the freedom to adapt and experiment without being tied to a single vendor.
By adopting this modular strategy, you can harness the full potential of your energy data. Advanced AI-driven tools can uncover hidden insights, optimize operations, and identify opportunities that might otherwise go unnoticed. At the same time, maintaining an independent data infrastructure allows for smooth integration of key processes like regulatory compliance, ESG reporting, and tariff calculations, all without the constraints of an all-in-one platform.
In the rapidly evolving energy landscape, flexibility is essential. By building an energy management ecosystem that encourages experimentation and innovation, you position yourself to continually improve and adapt. The journey doesn’t end with data collection—it begins there. A well-structured, independent data layer ensures that the insights gained today will continue to drive smarter decisions for years to come.