At Energy Twin, we’ve been working on a research project exploring how machine learning can be used for general fault detection. Like any good research, we aimed high, took an ambitious approach… and didn’t quite get the success we hoped for. But that’s part of the process! Instead of sweeping it under the rug, we want to share our journey—what we tried, what didn’t work, and what we learned along the way.
General Idea
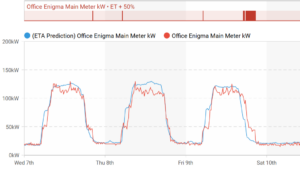
This project focuses on fault detection in air handling units (AHUs), with the broader goal of developing a machine learning-based tool capable of identifying anomalous behavior. In machine learning (ML) terms, this means detecting instances where actual measurements deviate significantly from model expectations.
Our key ambition was to create a generalized approach—minimizing human effort and ensuring that the method is not limited to AHUs but can be applied to virtually any HVAC equipment.
To achieve this, we followed two core principles:
- Independent modeling for each variable – Instead of building a single model for the entire system, we created a separate machine learning model for each measured variable, treating it as an individual prediction target.
- Fully automated model configuration – Both feature selection (i.e., determining model inputs) and model structure selection are automated, removing the need for manual tuning.
One of the biggest challenges in fault detection and diagnostics tools is the prevalence of false alarms. To address this, we designed our system to trigger alerts only when the machine learning model is operating within a known data range. In other words, we only flag deviations when similar conditions have been observed during the model’s identification period. If the model encounters previously unseen conditions, we discard the deviation, as we lack a reliable reference for expected behavior.
Diving into ML Details
Now, let’s take a closer look at the implementation. For model identification, we leveraged our Python-based Energy Twin tools, which already provide a strong foundation for fully automated modeling and fault detection. What made this project particularly ambitious was that everything—feature selection, model structure optimization, and anomaly detection—was handled without any human intervention. Once the process started, the only limiting factor was raw computational power.
The key components of our approach included:
- Automated feature selection – Using SHAP values and permutation importance, our system independently identified the most relevant inputs (independent variables) for each model.
- AutoML-driven model selection – The optimal model structure and hyperparameters were determined automatically, ensuring peak performance without manual fine-tuning (using AutoML principles).
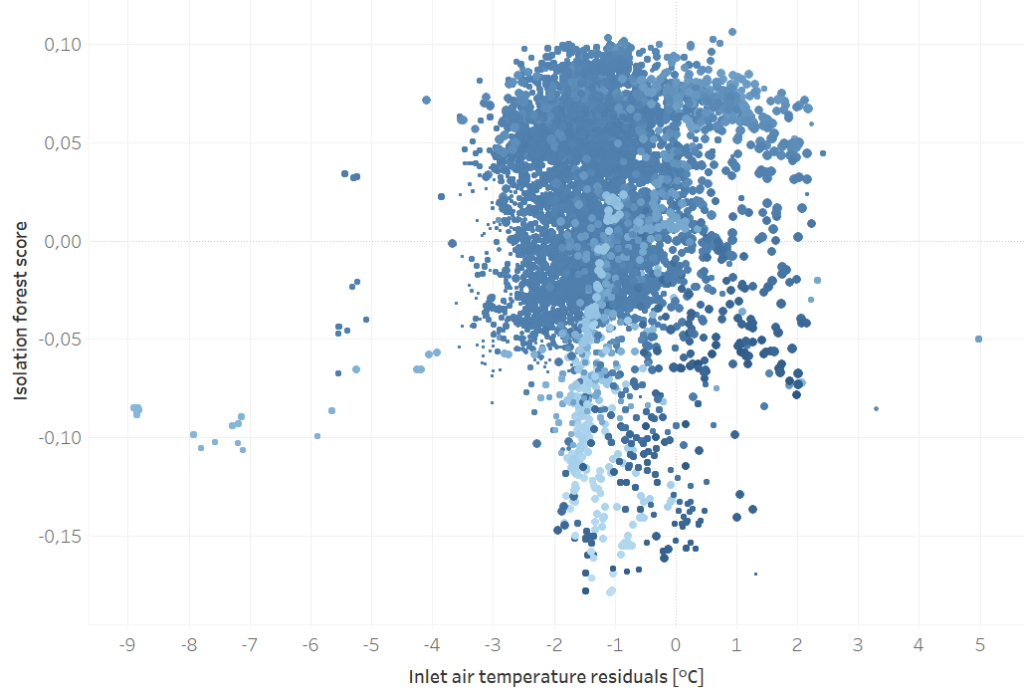
One of the major challenges was determining whether a model was extrapolating beyond known data—meaning it was making predictions in conditions it had never seen before. To address this, we incorporated Isolation Forest, an anomaly detection algorithm designed to identify novel or out-of-distribution data points.
In summary, for each measured variable, our system automatically deployed:
- A dedicated ML model trained to predict that specific variable using the most relevant inputs and an optimized model structure.
- An Isolation Forest model to assess whether the prediction was made within known data conditions or if the model was extrapolating into unfamiliar territory.